· Abraham · Forja · 9 min read
Anatomía de un turno de chat
Dos Modelos corriendo en paralelo, y las costuras que hay que coser para que una respuesta cálida, rápida y honesta parezca simple.
Cuando chateas a diario con un modelo pequeño, de los que caben en tu casa, te das cuenta que para resumir, traducir o redactar es más que suficiente. Pero hay un salto real frente a un modelo frontera en cuanto la conversación se complica o pide algo de profundidad.
Y a eso se le suman los vicios de la talla pequeña. El servilismo y las muletillas me resultan odiosos. Las alucinaciones aparecen donde menos las esperas y peor aún porque a veces no las detectas… he visto fallar un código postal, una capital, divagaciones que suenan seguras y son falsas. No es que el modelo sea malo, es que no puedes preguntarle cualquier cosa y esperar una respuesta sólida.
El reflejo inmediato es: démosle herramientas. Que consulte el correo, el tiempo, el calendario o la web, en lugar de inventárselo. Ayuda, pero no basta. Porque si además quieres que el asistente se sienta vivo y que conteste sin que la respuesta se eternice, que reaccione a cómo le hablas y no solo a qué le pides, las herramientas por sí solas no te lo dan. Hay que ir por otro camino.
Tres escenarios, tres respuestas distintas
En mi uso real, las peticiones caen casi siempre en uno de tres patrones:
- Charla casual: “Hola Alyss, hoy me duele la cabeza.”
- Charla con herramienta: “Alyss, ¿tengo facturas nuevas en el correo?”
- Las dos cosas a la vez: “Alyss, hoy no tengo un buen día, espero no tener facturas en el correo… y no sé si esta tarde debo llevar paraguas.”
Y espero respuestas estructuralmente distintas en cada uno:
- Algo corto y de ánimo. Nada más.
- Anticipación: “espera un momento, que consulto tu correo”, y luego el dato.
- Ánimo, anticipación, y dos herramientas (correo y tiempo) integradas en una sola respuesta coherente.
El tercer escenario es el más exigente, y deja claro que no basta con lanzar un prompt y rezar. Si tratas los tres casos igual, o haces esperar al usuario en el primero, donde no hay nada que consultar, o respondes en seco en el tercero, donde hace falta calidez mientras trabajas por detrás. Necesitaba que el asistente empezara a hablar como persona desde el primer token, y que decidir si toca herramientas no le costara el silencio de la espera.
Este es ese tercer escenario, resuelto de verdad por Alyss:
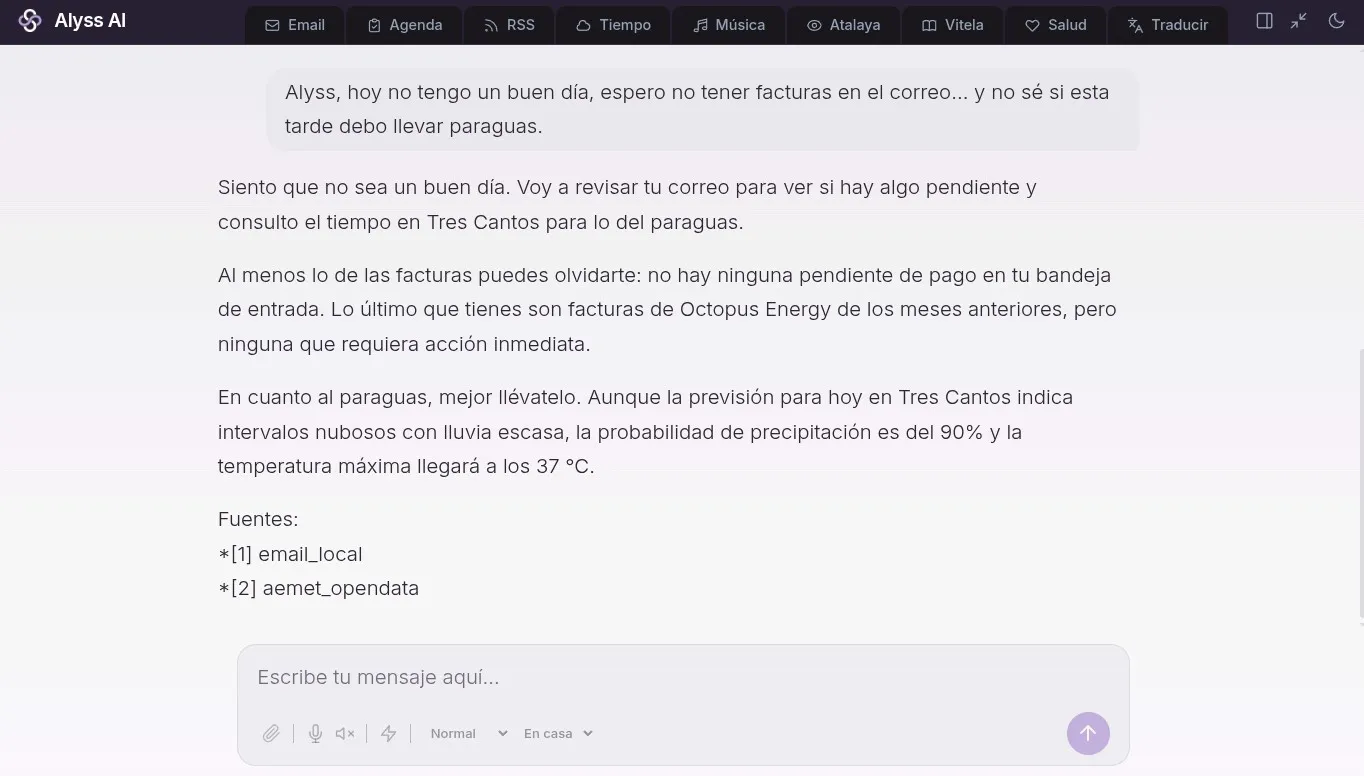
Fíjate en el orden: primero “Siento que no sea un buen día” (la parte humana), luego “voy a revisar tu correo… y consulto el tiempo” (la anticipación), y por último las dos herramientas, el correo y el clima, fundidas en una respuesta que cierra con un consejo. Creo que se consigue continuidad y una sola voz, y sin repetir la anticipación al pasar a los datos.
El enfoque: dos tarjetas, dos responsabilidades
La idea de fondo no depende de qué modelos uses, así que la cuento por roles. Tengo dos tiers corriendo en dos GPUs distintas, y lo que de verdad importa es qué hace cada uno y cuándo.
El reparto es asimétrico a propósito:
- El cognitivo es la voz. Es quien redacta la respuesta humana: el ánimo, el tono, la integración final de los datos en algo que suena a Alyss y no a un volcado de JSON. Quiero aquí un modelo que escriba con calidez, que tenga oído para el lenguaje.
- El ejecutor es el músculo determinista barato. No redacta para el usuario: detecta si la frase pide herramientas, extrae los parámetros (qué buscar en el correo, qué ciudad para el tiempo) y, más tarde, verifica. Aquí no quiero alma, quiero disciplina: un modelo que siga un esquema y devuelva JSON. No siempre lo clava —ningún modelo de este tamaño lo hace—, así que su salida nunca se da por buena sin validar; pero ese es otro tema. Es trabajo de fontanería, y para eso un 14B sobra.
Creo que es importante destacar la decisión de usar dos modelos diferentes: uno que narre bien, más grande, para que sea capaz de captar las sutilezas del lenguaje, y otro capaz de ejecutar las tools sin errores y lo más rápido posible. Muchas veces me recuerdo a mí mismo que esto no son modelos frontera, capaces de hacerlo todo bien en un solo turno.
Mi setup, junio de 2026. Cognitivo: Gemma 4 26B (MoE, 4B activos) en una Radeon 7900 XTX con ROCm. Ejecutor: Qwen3 14B en una RTX 5060 de 16 GB con CUDA. Las cifras de latencia que cito más abajo (≈0,65 s de apertura, ~6,6 s de turno completo) son de esta máquina. Los nombres envejecerán; el reparto cognitivo/ejecutor, no.
Lo importante es que no se ejecutan en cadena. Cuando llega “hoy no tengo un buen día, espero no tener facturas…”, las dos tarjetas arrancan a la vez sobre el mismo turno:
turno del usuario
│
├──► cognitivo ──► empieza a escribir la parte humana
│ "Vaya, siento que hoy no vaya bien… déjame ver si tienes algo
│ en el correo y si esta tarde necesitas paraguas" (streaming, token a token)
│
└──► ejecutor ──► ¿esto pide herramientas? sí: correo + tiempo
extrae parámetros ──► lanza los MCP en paraleloMientras el cognitivo ya está escribiendo las primeras palabras de ánimo en tu pantalla, el ejecutor, en la otra GPU y sin robarle ni un milisegundo, ya ha decidido que hace falta tocar el correo y el tiempo, y ha disparado esas consultas. Cuando los datos vuelven, el cognitivo los integra en un segundo tramo de la respuesta. El usuario nunca ve una pausa muerta: ve a Alyss empezando a hablar de inmediato, y luego “atando” los hechos.
Y no es una metáfora: la traza del turno lo enseña tal cual.
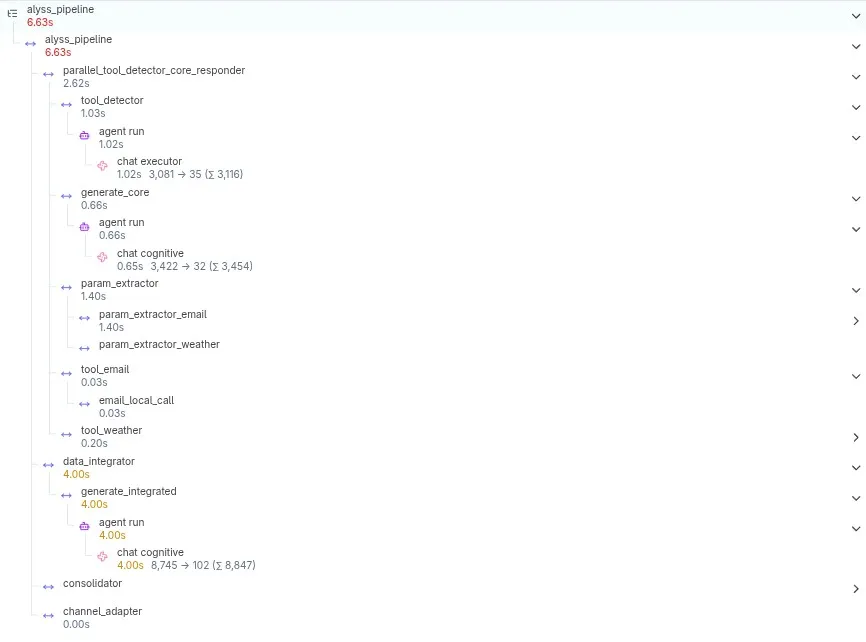
A destacar en la captura: el span se llama literalmente parallel_, y dentro el detector (tier ejecutor) y la apertura cognitiva corren a la vez, y esa apertura cuesta solo 0,65 s. Por eso Alyss empieza a hablar casi al instante. El grueso del tiempo está en el data_integrator final, esa segunda llamada cognitiva de 4 s y casi 9.000 tokens. El turno completo son ~6,6 s. Es decir: el paralelismo no hace la respuesta instantánea, hace que empiece instantánea. La presencia se gana en los primeros 0,65 s; la integración honesta de los datos cuesta lo que cuesta (en mi máquina actual el modelo va a unos 90 tokens/segundo).
Ese paralelismo es todo el truco de que se sienta vivo. Lo que mata la sensación de presencia es el silencio mientras decide qué hacer. Al sacar esa decisión a otra tarjeta que corre en simultáneo, el silencio se reduce considerablemente.
El reto: dos iteraciones que tienen que sonar a una sola
Partir el trabajo trae asociado su propio problema. Si el cognitivo abre el turno y luego un segundo paso el integrador cierra con los datos de las herramientas, son en realidad dos generaciones distintas del mismo modelo, separadas en el tiempo, y tiene que haber continuidad y sonar igual.
El primer problema es la repetición. El cognitivo ya dijo “un momento, miro tu correo”; si el integrador arranca con “como te decía, ya tengo tu correo…”, el usuario lee dos veces la misma frase y la ilusión de fluidez se rompe. La solución no es algorítmica: el integrador recibe en su prompt, literalmente, la primera parte ya emitida, con la instrucción de continuar desde ahí, nunca de recapitular. Va directo al dato. Afinar ese empalme es, en buena medida, trabajo de prompt, no de código.
El segundo es más sutil y me costó verlo: el cognitivo a veces anuncia que va a consultar algo que ya está resuelto en turnos anteriores. El usuario pregunta por el correo, el asistente contesta, y dos turnos después una variante de la misma pregunta dispara otra vez el “deja que mire tu correo”… cuando el dato ya estaba en la conversación. El reflejo fácil sería que el cognitivo se apoye en el historial para ahorrarse la consulta. Pero ahí hay una trampa peligrosa: los turnos anteriores pueden contener respuestas equivocadas o caducadas. Si el modelo da por bueno un “eso no se puede saber” de hace tres turnos, propaga un error en lugar de corregirlo.
Para remediarlo la regla es tener cautela, en los dos prompts a la vez: el cognitivo tiene prohibido prejuzgar desde el historial, si lo va a mirar, que lo mire, no que lo dé por sabido, y el integrador trata el historial como pasado, no como dato actual: si la consulta de ahora devuelve tres correos, la respuesta tiene tres, aunque un turno viejo mencionara diez. Prefiero el coste de una consulta de más antes que el de una respuesta confiada y falsa.
Las dos llamadas cognitivas (abrir y cerrar) caen sobre el mismo modelo, en la misma GPU, en un único slot. No es un problema, porque no corren a la vez: entre una y otra está el uso de herramientas, que ocurre en el ejecutor (otra GPU) o de forma determinista. Así que las dos llamadas nunca se solapan.
Hay otra parte fija: el estilo de escritura y la identidad de Alyss, unos ~2.000 tokens que la segunda llamada tendría que volver a procesar cada turno. Para evitarlo, los dos prompts comparten un prefijo byte-idéntico a propósito, de modo que Ollama reutilice su caché. Es un detalle de fontanería que no se ve en la respuesta, pero sin él se notaría bastante más latencia. Que las dos voces suenen a una, y que lo hagan rápido, tiene por debajo este trabajo de relojería.
Lo que esta arquitectura no resuelve (todavía)
Repartir el trabajo arregla la presencia y la latencia percibida. Lo que no arregla es que un modelo de 14B siga equivocándose: el ejecutor sigue capaz de inventarse un código postal si le dejas. Por eso, antes de que sus datos lleguen a integrarse, hay una segunda capa que los vigila: grounding, auditoría por confianza, reintentos selectivos. Pero esa capa es otra historia, con su propia lógica y sus propias decisiones, y la contaré en una pieza aparte: cómo verifico una respuesta cuando el modelo que la sostiene no es de fiar.
Aquí me quedo con la decisión de fondo, que es más simple de lo que parece: un modelo pequeño en local no debe imitar a uno frontera, debe dejar de hacer el trabajo que se le da mal.



