· Abraham · Forja · 7 min read
Investigación profunda (I): el flujo de una pregunta
El recorrido real de una pregunta por el modo de investigación profunda: un arquitecto la descompone, varios investigadores la atacan en paralelo, un escéptico verifica el grounding y un corroborador re-deriva cada cifra contra su fuente.
Al ejecutar un modelo en local se hace evidente que no alcanza el conocimiento de un modelo frontera; se nota, y mucho. Aunque le des la herramienta de búsqueda y navegación por internet, el modelo se queda corto cuando el tema es de verdad complejo o quieres más detalle. Por eso, igual que ofrecen ChatGPT o Gemini, me decidí a implementar mi propia investigación profunda en Alyss.
Decidí implementar una pipeline en paralelo, con sus propios pasos, que se integra en la pipeline principal de Alyss. Hay que diferenciar dos cosas, una es cómo piensa una investigación, es decir, descomponerla, buscar, verificar, redactar; y otra cómo navega por internet sin filtrarte a un tercero ni que te bloqueen. De manera que lo separo en dos partes y aquí trato sobre la estrategia y resolución.
Conste que el diseño es mío, resuelto sobre la marcha y por lógica de “divide y vencerás”: hacer resúmenes para no saturar al redactor, verificar los datos y corregir las deficiencias que los modelos imprimen al ser pequeños. Después comprobé que converge con cosas que ya existían —los modos de “investigación profunda” que ofrecen otros, o la idea de verificar cada afirmación por separado—; lo tomo como señal de que el camino era razonable, no como receta que copié.
Partamos de un ejemplo: “¿cómo afecta el tiempo de pantalla al desarrollo cognitivo de un niño de tres años?”
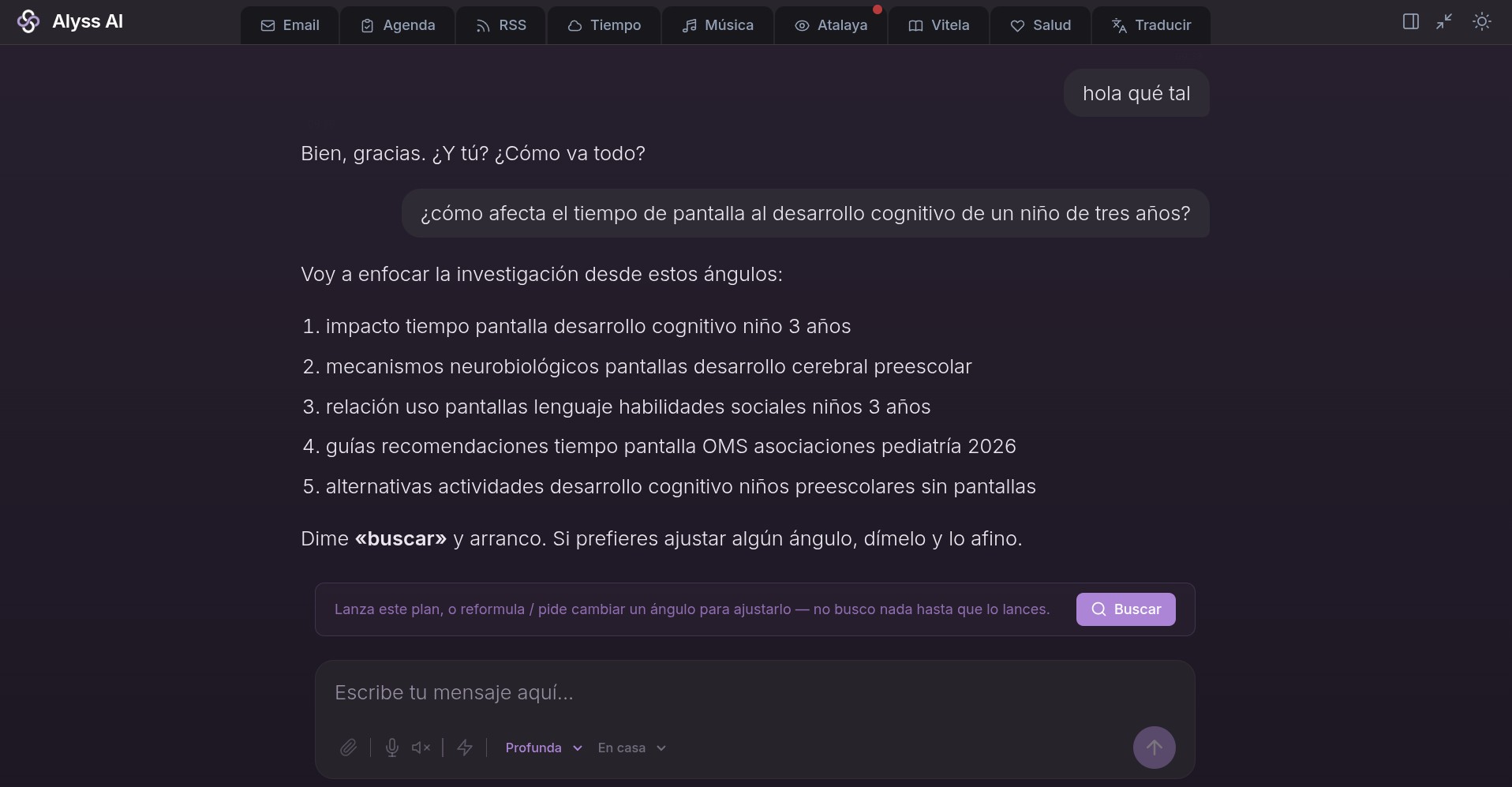
Fase 1. El plan
Se me ocurren varias estrategias para profundizar en esa pregunta, pero si hacemos una búsqueda directa tal cual en un buscador y tomamos los primeros 5 resultados, los leemos, sintetizamos, posiblemente nos encontremos un resultado plano y sin profundidad.
De manera que antes de hacer la búsqueda, la primera parada es el arquitecto, un modelo de razonamiento que descompone la pregunta en 3 a 5 ángulos autocontenidos. En el ejemplo del niño saldría algo así: efectos en el lenguaje, en la atención, qué dicen los pediatras frente a lo que dicen los estudios, el papel de los padres.
Y aquí va una decisión que me costó un par de iteraciones: mostrar primero el plan antes de ejecutar nada. El arquitecto escribe el plan propuesto, cierra el turno y espera. Tú lo lanzas, lo refinas con una crítica (“añade el ángulo del sueño”) o lo cancelas. Es el mismo patrón que uso para confirmar acciones destructivas: el sistema no se va diez minutos a abrir navegadores buscando lo que no querías.
Fase 2. Un investigador por ángulo, en paralelo
Aprobado el plan, se lanza un investigador por faceta, a la vez. Es decir, un quórum, como si fuesen varios ojos sobre el problema en paralelo: no un único hilo leyendo una página tras otra. Cada investigador trabaja su ángulo y sintetiza lo que encuentra.
Si una faceta falla, ya sea por webs caídas o por timeouts, no se traga el error en silencio: el resultado lo dice (“la búsqueda falló para esta faceta”, “se encontraron páginas pero no se pudieron sintetizar”).
Cómo navega cada investigador sin martillear los buscadores, cómo evita que lo bloqueen y cómo se queda con lo relevante de cada página —no con los primeros caracteres— es justo la fontanería que cuento en la segunda parte. Aquí me quedo en el qué: varios investigadores, en paralelo, cada uno con lo suyo.
Fase 3. El escéptico, en otra tarjeta
Con las facetas sintetizadas entra un escéptico: otro modelo, en otra tarjeta, que no sintetizó ninguna faceta ni va a redactar el texto final. Su trabajo es verificar el grounding: ¿esto se sostiene en lo que se leyó, o se lo está inventando el sintetizador?
Una sutileza que aprendí a fuerza de equivocarme: cuando el escéptico detecta un hueco de cobertura, la respuesta es re-buscar ese ángulo, no parchear el texto. Re-buscar arregla “faltaba el tema del sueño”. No arregla “esta afirmación no tiene soporte” —eso es problema del redactor, no del buscador, y meterlo en la cola de búsqueda solo añade ruido—. Distinguir esas dos cosas fue medio diseño del módulo. Y cuando re-busca, te dice si fue un refuerzo de un ángulo que ya salió (↻) o un hueco genuinamente nuevo (✚).
Fase 4. Corroborar cada cifra contra su fuente
Los modelos (locales) fácilmente omiten datos o incluso existe el riesgo de que alucinen, y he considerado necesaria la verificación de datos. Cada dato duro, una cifra, una fecha, un porcentaje, pasa por un corroborador: Chain-of-Verification explícito. Un modelo independiente, que no redactó nada, re-deriva el soporte de cada afirmación desde los pasajes en bruto etiquetados por fuente. Para cada dato emite un veredicto con uno de cuatro estados:
- Confirmado — dos fuentes distintas, o una primaria de autoridad.
- Una sola fuente — hay que atribuirlo, no afirmarlo a secas.
- En conflicto — las fuentes se contradicen; eso se expone, no se promedia.
- Sin soporte — ninguna fuente lo sostiene. No se afirma.
Y el veredicto no es la opinión del corroborador: el modelo solo señala qué fuentes apoyan o contradicen cada dato; luego una capa determinista cuenta los dominios distintos y consulta una tabla de autoridad (una fuente como el INE o el BOE basta por sí sola). De esa aritmética salen los cuatro estados, no de un “me parece”.
El redactor recibe esa disposición dato por dato, y una cifra “sin soporte” no entra como si fuera verdad. Si hay estudios que discrepan, el prompt obliga a dejarlo claro en la redacción. En todo momento se trata de evitar que el modelo afirme como veraces datos que no lo son.
Fase 5. La redacción, por secciones
Solo al final escribe el redactor, sección por sección, en streaming, ves el texto aparecer. Una pasada por faceta más una síntesis de intro y conclusión, todo a temperatura baja para que se ciña a lo encontrado y no improvise.
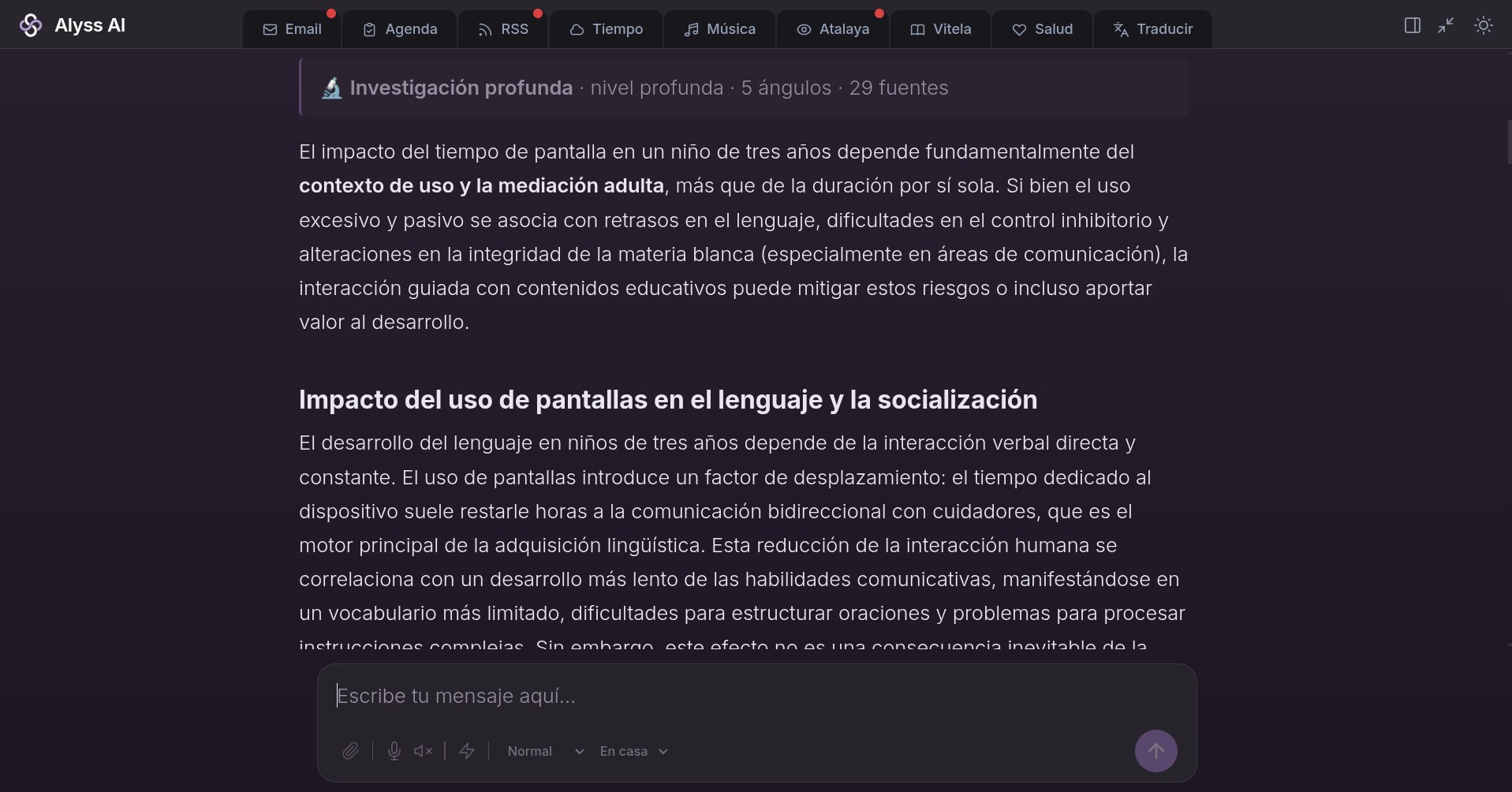
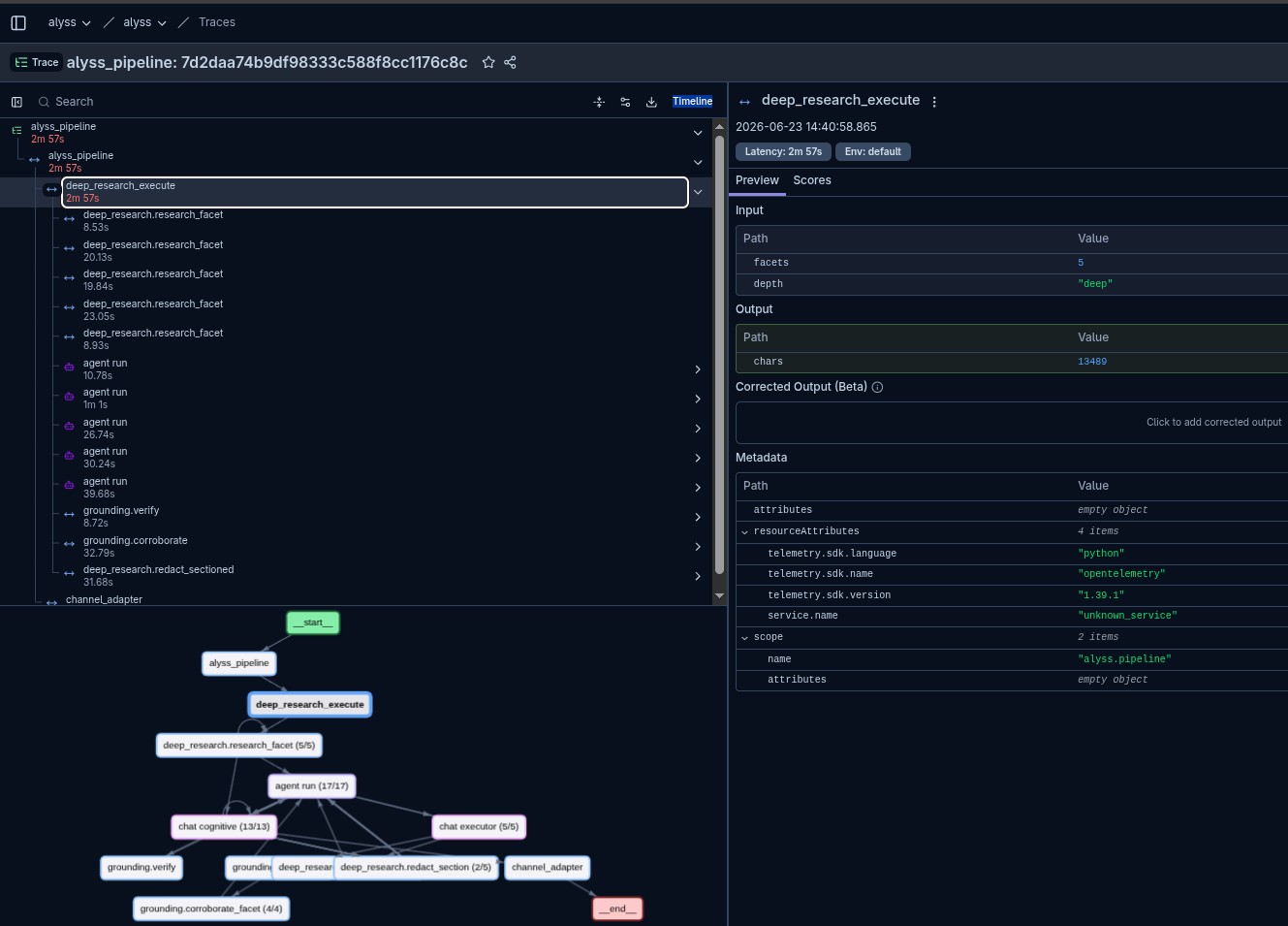
Con esta estrategia los resultados son buenos. Lento, eso sí: en la traza se ve el coste real, 2 minutos y 57 segundos para cinco facetas en paralelo, 29 fuentes leídas y casi 13.500 caracteres de respuesta. Para hardware doméstico y un Gemma de 26B me parece un buen resultado.
Pero no me fío solo de mi opinión, así que cojo la respuesta y se la paso a Claude Opus para que la audite como crítico honesto. Le pone un 7 sobre 10. La crítica es justa: las fuentes son casi todas secundarias (blogs, clínicas, divulgación) y falta jerarquía entre lo que está probado y lo que es solo narrativa popular. Y rescata el acierto que más me importa: el propio modelo avisa de qué cifras no tienen soporte sólido, que es exactamente lo que persigue todo este montaje.
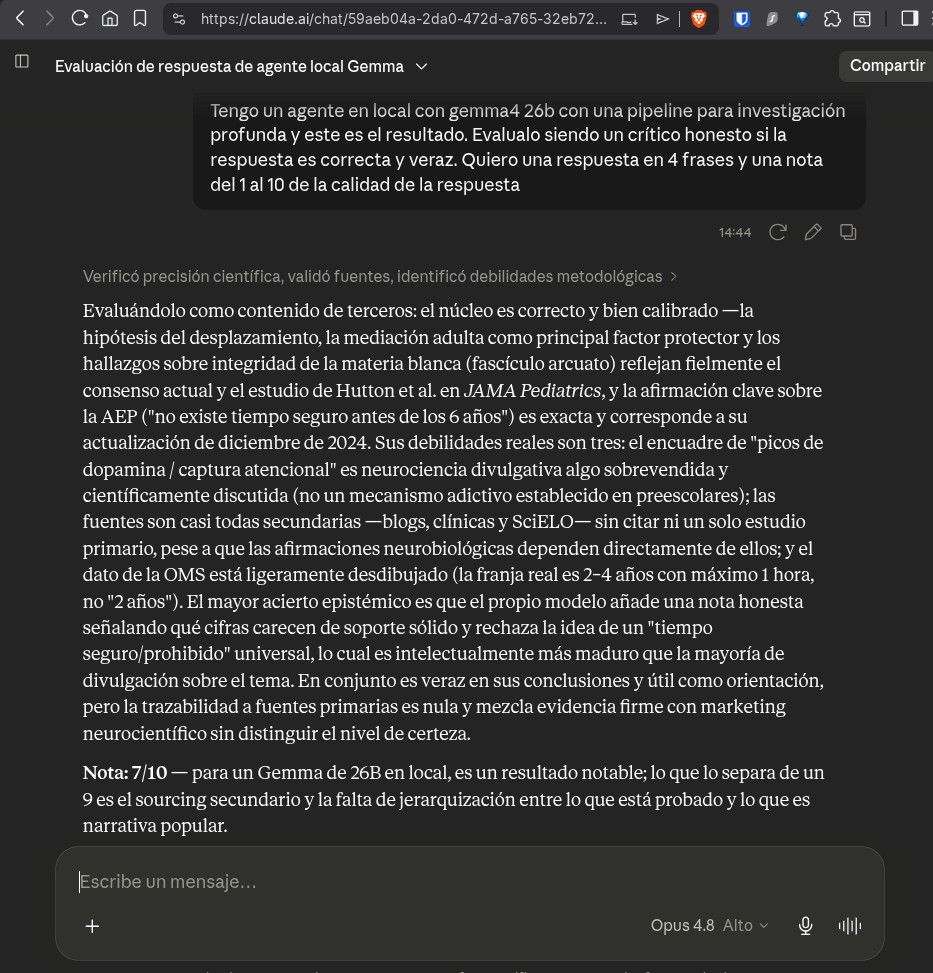
Ese 7 me viene bien, porque me dice con precisión qué falta. Y lo que le falta es la calidad de las fuentes, que no se resuelve razonando mejor sino en la fontanería: a qué sitios voy, de cuáles me fío y cómo llego a fuentes primarias sin que me bloqueen. De eso va la Parte 2.



