· Abraham · Alyss AI · 6 min read
A Little Genius
A six-step pipeline designed to transform the raw power of a local model into a reliable system

I haven’t written in a few weeks. I’m not a writer and I don’t particularly enjoy it, but writing helps me keep going — to sort out what’s in my head and move forward. These past weeks have been full of scratches, scrapes, stumbles and bruises. That’s been the running theme since I started all this.
I’m happy, because I’ve learned a lot along the way. But what has frustrated me the most, what has made me rethink everything and do far more trial and error than I’d like to admit, has been working with language models locally.
Here’s the trap: if you just chat with a mid-size local model, everything looks great. It responds coherently, reasons fluidly, seems capable of anything. The problem comes when you stop chatting and start building. When you put it inside a decision tree, ask it to use external tools, demand a specific response format, give it a role within a pipeline alongside other agents — that’s when it starts falling apart. Hallucinations that feel like a bad joke: “you have 3 emails from myboss@company.com”. Broken formats that wreck the next step. Prompting that grows increasingly defensive, longer, more fragile, trying to keep a tight leash on a model that just isn’t reliable when things get complicated.
After weeks of testing, I made a decision that goes against my principles: I switched to Gemini Flash 2.5. And everything started working. The hallucinations disappeared, tool usage became predictable, formats were respected. The difference was immediate and hard to ignore.
But data sovereignty isn’t negotiable for me. So I’ve come back to square one with a clear decision: I’m going to invest in hardware and use a 30B parameter model — something I can run myself. That’s the cost of sovereignty, and I accept it without hesitation.
Again.
I’ve started over. Again. I don’t mind, because every time around I learn new things and make better decisions. For instance, I dropped LangGraph and now use PydanticAI. I also discovered, with a certain amusement, that the path I’d arrived at intuitively already has a name: it’s called ReAct. My five steps aren’t original. They’re an answer to the need of taming my little genius — and it turns out others got there before me.
Because that’s genuinely how I see it. If you have a child who’s a genius and you ask them to do something complex, they won’t know where to begin. But if you guide them step by step, get them to think before acting, force them to verify what they’ve done and summarize what they know — things improve dramatically. That’s exactly what a good pipeline does with a language model: not blindly trusting its ability, but building the scaffolding that lets it use that ability well.
I’m still testing and I’ll keep testing. But this is what I’m building right now.
The Six Steps
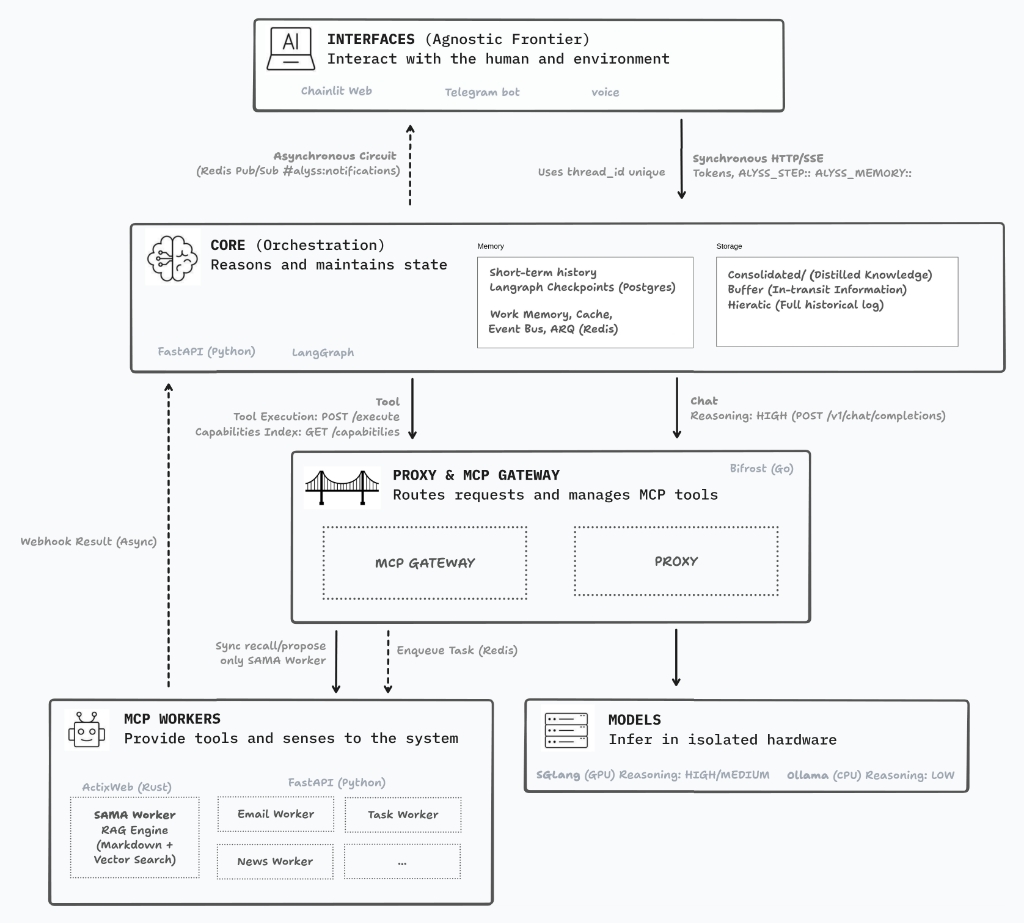
The pipeline actually has 6 steps, but it doesn’t always go through all of them. Depending on what you ask, Alyss AI can take different paths, skip verifications that aren’t needed, or pause to ask for clarification before continuing. In most conversations, though, the sequence looks like this.
Step 1 - Evaluate. Before doing anything, Alyss AI stops to understand what you’re actually asking for. Not just the words, but the intent behind them. Is this a concrete task? A personal conversation? A routine you already have defined, like your morning briefing? Is there something ambiguous that would require a question before it can answer well? This step is the conductor: if it misclassifies the intent, everything that follows works from false premises.
Step 2 - Anticipate. While it gets to work, Alyss AI immediately tells you it understood what you need and what it’s going to do. It doesn’t leave you staring at a blank screen for seconds. “Checking your email and the weather…” is already a response, even if the actual information hasn’t arrived yet. It’s a small detail, but it makes the interaction feel alive.
Step 3 - Act. This is where Alyss AI fires all the tools it needs, in parallel and each with a time limit. If it needs the weather, your emails, and the day’s news, all three queries happen at once — not one after another. Each tool also evaluates on its own whether what it retrieved makes sense, before handing off the result. The tools are MCP adapters: standardized interfaces to external services. They contain no domain logic; they only translate pipeline requests into structured data. The domain logic lives in the services, which are deterministic and unit-testable.
Step 4 - Consolidate. The results from all the agents arrive and a purely deterministic process — no model — aggregates them. It calculates a global confidence score as the weighted average of individual confidences. It detects conflicts between agents: if the weather one says “sunny” and the news one says “weather alert”, something doesn’t add up.
Step 4B - Verify (conditional). This is the step that took me longest to understand, and that has changed my thinking about models the most. If the global confidence falls below 0.7, a verifier model steps in for a deeper evaluation: do the data actually support what’s about to be said? Is there any contradiction with the user’s implicit premises? Is there enough information to answer well, or is it better to admit there isn’t?
The verifier uses a different model than the interpreter (Gemma 4 for verification, Qwen3 for interpretation) to avoid confirmation bias: a model that fact-checks itself tends to agree with itself.
Step 4C - Reflect (conditional). If the verifier decides the data is recoverable but insufficient, the system critiques itself and reruns only the agents that failed, with improved instructions. Up to two retries. If after that there’s still not enough data, it admits its ignorance usefully: it explains what it knows and what it can’t know.
Step 5 - Interpret and respond. With everything verified, Alyss AI generates the response. But it doesn’t generate a single version: depending on the channel you’re speaking from, the response adapts automatically. Listening to it by voice is not the same as reading it on Telegram or working with it on a screen. Alyss AI knows this, and each channel gets exactly what it needs.
What ties these six steps together isn’t just the technical architecture. It’s a philosophy: don’t trust that the model knows what it’s doing — build the scaffolding that lets it do it well. That’s what I’ve been spending months learning how to do.
Step 6 - Post-process style. Depending on the channel, the response goes through a style filter. For voice, it’s a rule-based transformation without any LLM: adjusting rhythm, removing constructions that don’t work when heard aloud, making sure no sentence exceeds twenty words. For rich channels, a lightweight model applies Alyss AI’s personality according to its style file. The key is that this step only colors what already exists: it doesn’t decide what to say, only how to say it.
That’s it for today. I’m going to go play with my little genius. The real one. The four-year-old. He doesn’t hallucinate, but he doesn’t accept prompts either.
Author's Note: English is not my mother tongue. While I lean on digital tools for translation, I personally oversee every word to ensure that the human intent and the original soul of my Spanish writing remain intact. This is a journey of ideas, not just algorithms.